In the ever-expanding world of artificial intelligence, one of the most intriguing frontiers is generative modeling — machines creating novel data that looks like it was drawn from the real world. Whether it’s producing artwork, synthesizing voices, or crafting realistic photographs, the magic often starts with a class of models known as Variational Autoencoders, or VAEs.
But what makes VAEs so special in a sea of deep learning architectures? Why are they often chosen when stability and interpretability matter more than sheer photorealism? This blog aims to break down VAEs in an approachable, comprehensive way — with original language and fresh insights that you won’t find copy-pasted across the web.
Autoencoders: A Familiar Starting Point
Before diving into VAEs, let’s briefly explore their ancestors: autoencoders. At their core, autoencoders are neural networks designed to compress and reconstruct input data. Think of them as a funnel — an input is squeezed through a bottleneck and then expanded back to its original form.
The structure is simple:
- An encoder shrinks the input into a lower-dimensional representation.
- A decoder attempts to reconstruct the input from that compressed form.
Although useful for tasks like denoising or feature extraction, standard autoencoders aren’t particularly creative. They learn to repeat, not to invent.
The Variational Leap
VAEs extend the concept by introducing probability into the mix. Instead of assigning each input a fixed point in latent space, they represent it as a probability distribution — most often a Gaussian.
This subtle shift makes a big difference: VAEs can now sample from this space, creating new data points that are plausible, yet different from anything seen during training. It’s like learning the rules of a language and then forming brand-new sentences rather than just memorizing existing ones.
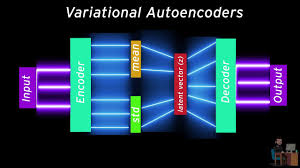
How VAEs Actually Work
A VAE comprises three components:
- Probabilistic Encoder
Instead of outputting a vector directly, it returns the mean and variance of a Gaussian. This represents a distribution over possible encodings. - Latent Space Sampling
To get a usable vector from this distribution, we sample a point. But neural networks don’t naturally support random operations in the middle of training. That’s where the reparameterization trick comes in — a clever workaround that lets gradients flow through stochastic layers. - Probabilistic Decoder
This part tries to reconstruct the original input from the sampled latent vector. Because the encoder and decoder are trained jointly, the model learns to generate realistic outputs from plausible latent codes.
A Bit of Math (But Not Too Much)
The learning goal for a VAE is maximizing the likelihood that it can reconstruct inputs while ensuring the latent space is structured. This is done by optimizing a custom loss function, which combines:
- Reconstruction Error: Measures how well the output matches the input (e.g., pixel-wise difference for images).
- KL Divergence: A penalty that keeps the learned latent distributions close to a standard normal distribution. It prevents the model from memorizing and forces it to generalize.
Together, they form the Evidence Lower Bound (ELBO) — a quantity that guides training.
Latent Space: The Model’s Imagination
The “latent space” in a VAE is not just an abstract mathematical idea. It’s where the model stores everything it has understood about your data. When trained on handwritten digits, each region of this space might correspond to different styles, sizes, or rotations of numbers.
Want to generate a new “9”? Just pick a point near known “9” vectors and decode it. The smooth, continuous nature of this space allows interpolation — morphing one data point into another by walking through the space between them.
This isn’t just cool — it’s immensely useful in applications like:
- Morphing facial expressions
- Blending music genres
- Transitioning between art styles
Real-World Uses of VAEs
Unlike GANs, which are often used for photorealistic imagery, VAEs shine when:
- Interpretability matters
- Controlled generation is needed
- Smooth transitions between samples are desired
Some powerful use cases include:
Bioinformatics
VAEs help model gene expression data to understand diseases or predict mutations.
Art & Style Fusion
By training on paintings, VAEs can mix visual styles, giving rise to hybrid artworks.
Anomaly Detection
Since they learn a compressed version of “normal” data, inputs that deviate too much from this are easy to flag.
Cognitive Modeling
VAEs are used in neuroscience to simulate how brains might represent abstract concepts like color, shape, or sound.
Strengths and Shortcomings
Advantages
- Stable Training: Unlike adversarial models, VAEs are less prone to instability.
- Explorable Latent Space: Makes them perfect for research and creative work.
- Principled Design: Built on solid mathematical footing (variational inference).
Weaknesses
- Less Sharp Outputs: Image quality can be blurry due to pixel-wise loss functions.
- Overly Smooth Samples: Sometimes fails to capture fine-grained structure.
- Sensitive Balance: Tuning the weight between reconstruction and KL terms is crucial.
Beyond Basics: Variants and Innovations
Researchers have extended the vanilla VAE in multiple directions:
- β-VAE: Adds a scaling factor to the KL term to improve disentanglement.
- Conditional VAE (CVAE): Generates data based on auxiliary labels (e.g., “draw a cat”).
- Vector-Quantized VAE (VQ-VAE): Replaces the continuous latent space with a discrete codebook, often improving quality for images and speech.
These variants show that the VAE is not a static architecture, but a growing family of models with increasing flexibility and power.
Final Thoughts
In a world obsessed with realism and photorealistic images, it’s easy to overlook the elegance and structure of Variational Autoencoders. They might not always produce the flashiest results, but what they offer is arguably more profound: a clear, navigable, and interpretable view of the data’s underlying structure.
If you’re venturing into the world of generative AI and want a well-grounded, stable, and insightful model to work with — start with VAEs. They’re more than just a stepping stone; they’re a canvas for creativity, exploration, and understanding.